
Android Architecture: Runtime Centric Thinking
For at least 7 years I have been playing with “alternative” Android architectures in a professional context. This blog post is a brief overview to an architecture I have been using for the last two production projects for which I was Android Lead and outlines a high level introduction to a production-level runtime-centric application.
I will note at the start I am not attempting to persuade anyone to use this approach over any other, but rather:
- Understand my own thoughts better through writing
- Share something which has worked well for me which others may find interesting
I imagine it may raise more questions than it answers, and if so please leave a comment and I can expand any concepts if desired.
Motivation
My original motivation to think about alternative Android architectures was due to me often feeling there were personally unexplored and advantageous ways to structure certain types of applications on an OS like Android, which has a number of idiosyncrasies including application component lifecycles, application component instantiation, difficulty in test automation and so on.
In the 12 years I have been a professional Android developer I have seen some common examples of where complexity has been layered on top of some of these areas in the aim of making them easier to deal with on a day to day basis when often an arguably simpler divergent approach has been overlooked. For some quick fire examples I would include here:
- Test time OS level faking frameworks vs OS abstraction at build time
- Complex lifecycle aware asynchronous view-level listeners as opposed to rendering immutable states
- Complex 3rd party dependencies utilised for threading purposes as opposed to thread abstraction
- Fragments vs thin views cough
I found that there were often common solutions to common problems but which often came with an additional baggage of increased run / build / test time complexity. Instead of thinking in terms of surface level solutions my mind kept wondering back to thinking about what a headless application runtime would work, and how it could potentially solve a lot the day to day issues with clean simple code. This of course is a radical departure from most Android applications, and certainly from how I was structuring my own.
For the kind of applications we were building, relatively simple backstacks, multiple application level event emitters, lots of platform agnostic domain logic, I suspected we could do better by re-evaluating our approach to application architecture from first principles.
Some of the specific requirements within the domain I was working and the development practises I wanted to adopt included:
- Reliable sensitive data management
- Clear event handling logic for a number of event sources (background services, external hardware, internal sensors, remote services)
- Clear logging, and a record of application flow and related event handling resolution
Additionally some of the areas I felt the architecture could aid in simplifing development included:
- Writing and execution of Test Driven Development acceptance tests
- Having to think about the Android application component lifecycle
- Concurrency
- Dependency instantiation and resolution
I should note I / we were putting effort into finding out what architecture would work well with our specific applications and requirements in mind. This blog post is not trying to suggest this is a good general architecture to use for day to day applications, but it is trying to suggest it’s a good fit for some and has some originally unintended benefits.
Re: MVI
Note: You will probably notice that there are similar concepts spoken about in this post as there are in MVI architecture. MVI as a concept did not exist 7 years ago when we were thinking about what approach to take, and it’s always fascinating when different parts of a community come up with similar solutions to similar problems around the same time. This this is also testament to the architectural principles shared by both MVI and Redux (more on that later) for simplifying architectural thinking. This posts talks at a high level about other principles that also worked well for us in practise with these kind of architectures.
For myself a fast, clean and comprehensive test suite was a must and I feel runtime architectures have an upper hand here in practise. A goal of mine has always been to define the domain logic and flows in a standalone manner i.e. completely separate from the Android OS & framework, which allows for fast development and testing in my experience. MVI does not enable this in my experience.
It’s interesting to note that MVI as an approach is inter-operable with popular architectures such as MVP and MVVM (as excellently described in the talk MVWTF: Demystifying Architecture Patterns by Adam McNeilly) as it essentually takes similar root principles from Flux / Redux and applies them at the feature level. This blog posts however talks more about a wider application level architecture. The application level approach introduced in this post may be a better fit for applications which are best / well suited to being modelled by a finite-state-machine, more below.
Building Blocks / Principles
As mentioned above, for brevity I am opting to not talk about each of the below architectural concepts / building blocks in depth. If there is any desire for me to I can expand on any particular area in a subsequent post.
From previous experience I had the following tools in my logical tool-box which I felt could add value in this architectual design process:
Finite State Machines (FSM)
FSMs are really useful constructs to:
- Understand what effect an Event should have on a system when it’s processing is contextual
- Ensure that sensitive memory is cleared for all exit paths from a particular application state or flow
- Perform set operations when states or state-groups are entered / exited
- Facilitate technical design and visualisation via UML state charts
For me, FSMs sometimes can encapsulate logic around the above points with a conciseness & clarity that nothing else comes close to. Sensitive data clearing (point 2 above) was really where a lot of my architectural thinking originated from and then my subsequent realisation that it’s quite painful to put an FSM at the heart of a traditional Android application architecture. Trying to solve this problem led me to a lot of the below principles which in practice work nicely with an FSM centric application.
Unidirectional Data Flow
Unidirectional data flow makes life pretty simple in many ways. Fundamentally it’s about formalising how data flows through an architecture, which for us means the View layer emits Actions / Events, processed by the core of the application, which emits states / presentation-models for the View to render. For a brief high level intro check out The Case for Unidirectional Data Flow.
Immutable Data
Immutable Data removes the possibility of state based bugs where multiple objects hold references to shared immutable data and therefore also reduces the possibility for concurrency issues also. Both of these are huge wins for me.
Thin Views
Thin views and single Activity architectures have been spoken about for many years. The motivations were stronger years ago due to developers often wanting to manage their own backstacks outside of using the FragmentManager, but also as it was just plain simpler. For me, I found simple “thin views” i.e. very little logic apart from rendering some immutable object was generally all that was required.
Concurrency Abstraction
I find concurrency really interesting within the Android domain as we have loads of choices, standard Java primitives, Android abstractions, 3rd party libraries like RxJava, Kotlin’s Coroutines. Each has its own set of pitfalls, each valuable in its own way, none a silver bullet or panacea. It’s safe to say that it’s a complicated area, and one which is easy to introduce tricky race-like hard-to-debug Heisenbugs. On top of that it’s easy to turn out complex code in this area due to an allegiance to a certain approach or when trying to mush together concurrent & asynchronous code with the Android lifecycle.
I have recently found it useful to experiment with architectures which allow us to isolate the concept of concurrency so developers do not really need to even think about it on a day to day basis, and this is something I wanted to further explore. The below Command Abstraction allows us to do just this.
Command Abstraction
To decouple the trigger of execution of a core chunk of biz logic from the creation, dependency resolution & scheduling of the object that will perform it, I find the Command pattern can be really useful.
This also allows us to:
- Set a project convention for how we encapsulate core use-cases and therefore aid in the automated-test writing process
- Isolate the code which perform the instantiation of the most complex highly-dependant objects in our application and therefore give us more choices around how we perform DI
- Encapsulate the threading strategy for the application
Inspiration from Redux
Additionally to the above, the following concepts from Redux are valuable mainly due to increased testability, behaviour reproducibility and transparency of execution.
- Majority of the application data & state is held in a flat immutable
DataStore - Everything that happens is represented as an
Action - A single
reducerfunction, which takes anActionandDataStorewill emit a newDataStore
Note: instead of DataStore or similar redux-like naming, we use the term RuntimeData is the rest of this post.
Serial Event Processing
Processing application events serially (or Actions in Redux terms) removes many potential race conditions.
The Concept Of A Standalone “Runtime”
When thinking about an application which has a state model at the center, and a single entry point to effect changes to that data and pluggable platform agnostic UI or framework level observers for me the term “Runtime” fits well.
This is the core of the application that codifies all the business logic and the abstract UI representation, but generally does not care what’s executing it or interfacing with it but just how it behaves in various Event driven scenarios. This is in contrast to an application architecture that is driven by UI or system components i.e. Activity transitions which kick of loading via ViewModels with similar lifecycles.
Implementation Overview
RuntimeKernel
At the center of this Runtime centric architecture we need something responsible for:
- serial processing of incoming
Actions¹ - the calling of a core
reducer() - handing off of
Commands - Holding of the core application state
This encapsulation is named the RuntimeKernel as it’s the core of the Runtime. Psudocode can be found below.
¹ As can be seen in the above code snippit, all incoming Actions are marshalled to a main thread in the context of the Runtime. The Runtime maintains it’s own main loop so it behaves the same regardless of the execution environment i.e. JVM vs Androids ART, and therefore aids the reliability of JVM based automated testing.
Visual overview
Hopefully a lot of the concepts shown in the below visual representation make sense in terms of the context provided above. As always let me know in the comments if something is unclear.
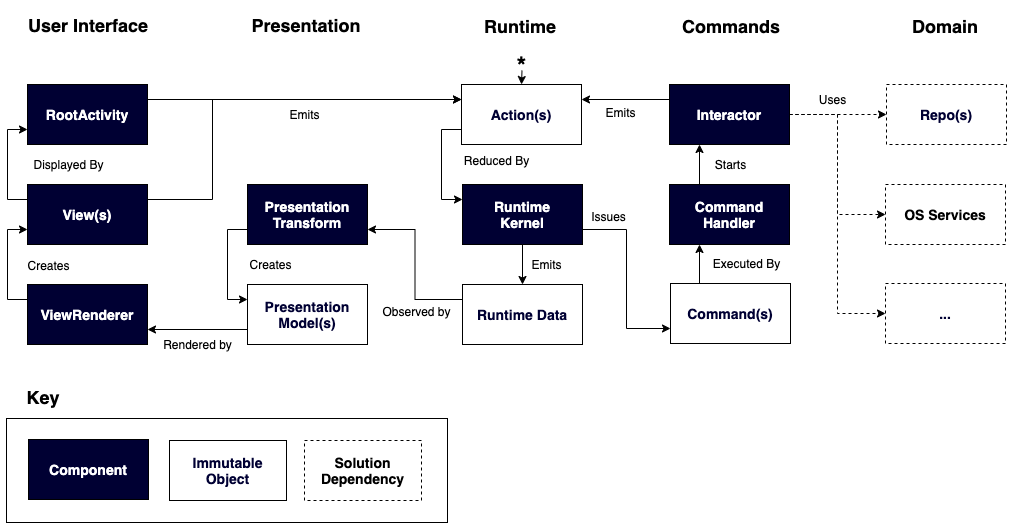
A note on depedency resoution
I have been using Dagger (and Dagger 2) for several years. It can be a real valuable tool and also it can be pretty confusing at times. I have found most developers are comfortable with some aspects of it and not with others (me included). For junior developers I have found it can be a bit of a learning hurdle also which I completely sympathise with as even as an experienced developer I often find myself wrangling with it.
DI, like many things in development, is one of those subjects that can easily trigger a mildly heated debate often with strong opinions being voiced from different opposite sides of the fence i.e. “Always use DI framework X” to “Only use a DI framework when absolutely necessary”. Having observed the pains of Dagger and always striving to isolate or remove complexity from the codebases I am working on (simplicity is happiness) I experimented with combining manual DI with the Runtime centered thinking and I was happy to discover they seem to work together very nicely indeed.
In practise, the class instantiation and dependency resolution all happened inside a RuntimeFactory class which created the core RuntimeKernel. Part of this was creating the CommandHandler which created all the on-demand Interactors.
This code was super simple to understand, super simple to provide test fakes for (via RuntimeFactory.build parameterisation) and super easy to debug, and therefore I was super happy :)
Reflection on usability
Reflecting on pros and cons post implementation, I feel it’s been a very successful experiment. In practise the pros include:
- Enabling fast, clean JVM based acceptance testing
- Removing the spread of concurrency complexity
- Being able to represent the application in a standard UML statechart
- Not having to do workarounds to avoid Android lifecycle issues
The cons include:
- No standard architecture requires more onboarding time, no one who joined the team had a common reference point
- Some boilerplate
For me, the pros significantly outweigh the cons so I am really excited about having a chance to use this approach again where appropriate. Developers who joined the team half way though the project found it took a few months to get their head into the concepts and approach, but then generally were converts. They appreciated the design principles and associated benefits and wanted to adopt them in new projects that were kicking off which they had sole design control. For me was a great seal of approval.
An unintended positive side effect of the above was the simplification of general code due to the threading confinement, I really found myself not thinking about concurrency much at all in day to day development.
Hopefully this blog post has some thought provoking aspects, please let me know if you have any questions or comments below!